搜索到
2
篇与
clickhouse
的结果
-
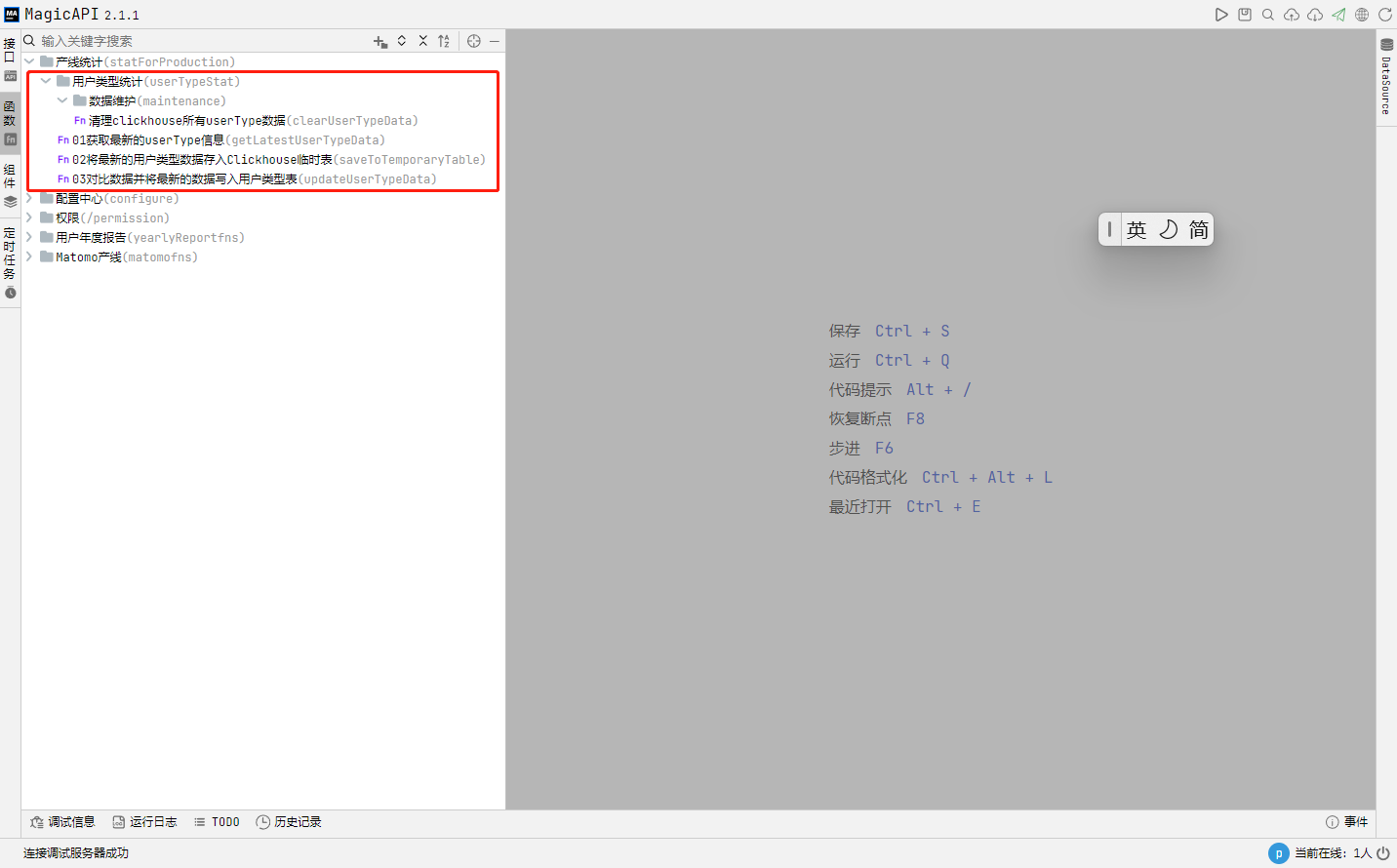
 基于 Magic-api + Clickhouse 实现业务数据更新的项目记录 背景介绍项目有用到 Clickhouse 作为数仓,存储一些用户日常业务产生的大数据,下面先简单介绍一下我们这个任务的需求背景:我们的每个用户都会归属于某个用户组,并基于用户所在的计费组织实现产品使用过程中的消费等情况。而按照系统的设定用户初始注册时是没有归属用户组的,计费组织的主账号可以在控制台将用户绑定到该计费组下,也可以解绑,解绑后也可以绑定到其他用户组。为了更好的这个变更情况,我们在 Clickhouse 添加了一张名为 user_type 的表,每次该数据变更都会新增一条记录,该表的结构如下:CREATE TABLE user_type ( `user_id` Nullable(String), `present_type` Nullable(String), `pay_type` Nullable(String), `group_type` Nullable(String), `start_date` Nullable(Date), `end_date` Nullable(Date), `uni_key` Nullable(String) ) ENGINE = Log;实现方案本项目初期由使用 dbt + Clickhouse 的方式来实现,但是经实践运行一段时间后发现 dbt 做数据同步很方便,但是要添加一些业务逻辑就显得很棘手。为了解决 dbt 的问题,我们使用已搭建的 magic-api 来实现这个数据的更新,由于相关数据仅需一天一更新即可,所以我们可以直接利用 magic-api 自带的定时任务机制来实现更新。技术细节为便于相关业务逻辑在接口和定时任务中复用,我们将核心代码写在函数模块中:相关步骤核心代码如下步骤:1、从计费系统获取最新的userType信息var statSQL = `select e.*, CONCAT(e.user_id,'-',e.present_type,'-',e.pay_type,'-',e.group_type,'-',date_format(e.start_date,'%Y-%m-%d')) as uni_key FROM( SELECT a.user_id, CASE WHEN EXISTS ( SELECT 1 FROM ( SELECT t1.user_id user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id UNION SELECT u2.user_id user_id from b_user as u1, b_user as u2 where u1.group_id=u2.group_id AND u1.user_id != u2.user_id AND EXISTS( SELECT 1 FROM (SELECT t1.user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id) c WHERE c.user_id = u1.user_id ) ) d WHERE a.user_id = d.user_id ) then 'pay' else 'no pay' END as present_type, CASE WHEN EXISTS( SELECT 1 FROM( SELECT t1.user_id FROM b_user t1 , b_group t2 WHERE t1.user_id=t2.pay_user_id AND t2.pay_user_id IS NOT NULL )b WHERE a.user_id = b.user_id ) THEN 'master' ELSE 'slave' END as pay_type, CASE WHEN EXISTS(SELECT 1 FROM(SELECT t1.user_id FROM b_user t1 WHERE t1.group_id IS NOT NULL)b WHERE a.user_id = b.user_id) THEN 'group' ELSE 'no group' END as group_type, CURRENT_DATE as start_date, DATE(null) as end_date FROM b_user a )e` return db['NB'].select(statSQL)2、将上一步获取到的信息存储到Clickhouse 的一张临时表import log; import cn.hutool.core.date.DateUtil; import '@/statForProduction/userTypeStat/getLatestUserTypeData' as getLatestUserType; // ------------------- 一、创建临时表 ------------------- const TEMP_TABLE_NAME = 'user_type_temp' var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${TEMP_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${TEMP_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${TEMP_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // ------------------- 二、获取最新的用户类型数据 ------------------- log.info(`============ 开始从计费系统获取最新的用户类型数据,该操作耗时较长,请耐心等待 ============`) var timer = DateUtil.timer() const userTypeList = getLatestUserType() log.info(`getLatestUserType cost time: ${timer.intervalPretty()}.`) // ------------------- 三、将数据存入临时表 ------------------- const BATCH_INSERT_COUNT = 1000 // 分批次入临时表,一次插入记录条数 var timer = DateUtil.timer() const allDataCount = userTypeList.size() if (allDataCount > 0) { log.info(`开始导入数据到临时表,待导入的总记录数为:${allDataCount},预计分${Math.ceil(allDataCount/BATCH_INSERT_COUNT)::int}批导入。`) const willInsertArr = [] var insertSQL = `insert into ${TEMP_TABLE_NAME}(user_id,present_type,pay_type,group_type,start_date,end_date,uni_key)` // 分批次插入临时表 for (index,userTypeItem in userTypeList) { willInsertArr.push(`('${userTypeItem.userId}','${userTypeItem.presentType}','${userTypeItem.payType}','${userTypeItem.groupType}','${userTypeItem.startDate}', null,'${userTypeItem.uniKey}')`) if (willInsertArr.size() === BATCH_INSERT_COUNT) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() log.info('Batch insert:' + index) } } // 不满整批次数据单独处理 if (willInsertArr.size() > 0) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() } } log.info(`insert latest user type to Temporary Table cost time: ${timer.intervalPretty()}.`) return true3、将临时表数据跟前一次最新的用户数据对比后,将有变更和新增的数据写入user_type表import log; import cn.hutool.core.date.DateUtil; const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据,已在上一步获取数据完毕 // 一、从user_type表获取所有用户最新的用户类型数据并插入到用于计算的临时表 // 1.1 新建临时表,用于存储每个用户user_type 表中最新的用户类型数据 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // 1.2 将最新数据写入临时表 // 该方式在数据量较大的情况下极有可能导致内存溢出,拟采取其他方案:在user_type 数据初始化的时候,将最新的用户类型数据存储到user_type_latest表,对比更新完成后将临时表的数据更新到user_type_latest便于下次对比 // const insertLatestDataSQL = `insert into ${LATEST_TABLE_NAME} SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key // FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp // WHERE user_type.start_date = temp.latestDate and uid = temp.uid2` // db['CH'].update(insertLatestDataSQL) // 二、两个临时表的数据做对比,并将最新数据更新到 user_type var timer = DateUtil.timer() // 2.1 更新有变更的数据 const changedInsertSQL = `insert into user_type select tuts.* from ${LATEST_TABLE_NAME} tutl left join ${TEMP_TABLE_NAME} tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type` timer.start("insertChangeData") db['CH'].update(changedInsertSQL) // 2.2 新增用户数据直接插入 timer.start("insertNewData") const insertNewUserSQL = `insert into user_type select * from ${TEMP_TABLE_NAME} tuts where tuts.user_id not in (select tutl.user_id from ${LATEST_TABLE_NAME} tutl) ` db['CH'].update(insertNewUserSQL) // 三、如果有数据更新,则将临时表的数据替换latest表 // 3.1 清理已有的数据 const truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) // 3.2 从临时表导入最新的数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) log.info(`insertChangeData cost time: ${timer.intervalPretty('insertChangeData')}`) log.info(`insertNewUser cost time: ${timer.intervalPretty('insertNewData')}`) // 四、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) return true 定义好相关函数后,我们可以直接在接口中用起来了,为此我定义了两个接口,一个接口用于数据初始化,一个接口用于手动更新数据:接口定义01数据初始化import log; import '@/statForProduction/userTypeStat/maintenance/clearUserTypeData' as clearUserTypeData import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据 // 一、清空所有user_type表的数据 clearUserTypeData() // 二、一次性写入所有 saveToTemporaryTable() // 三、将临时表的所有数据一次性写入user_type 表作为初始数据 const initialUserTypeDataSQL = `insert into user_type select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialUserTypeDataSQL) // 四、将数据写入最新用户类型表,便于下一次做数据比对 // 4.1 基于 user_type 表 创建 user_type_latest 表 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张 if (checkExistRes.size() === 0) { var createLatestTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(createLatestTableSQL) } else { // 表存在则先清空表的数据,便于下一步将最新的用户类型数据存入该表 var truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) } // 4.2 插入该表的初始数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) // 五、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) 02手工同步用户类型数据/** * 本接口用于手工临时同步数据用,日常使用定时任务自动同步操作即可 */ import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable import '@/statForProduction/userTypeStat/updateUserTypeData' as updateUserTypeData saveToTemporaryTable() updateUserTypeData()添加定时任务本任务用到的部分 Clickhouse SQL-- 判断数据表是否存在 SELECT 1 FROM system.tables WHERE database = 'dw' AND name = 'temp_user_type_session' -- 根据user_type 表创建一张名为 temp_user_type_session 的临时表 CREATE TABLE temp_user_type_session as user_type; -- 清空某数据表中的所有内容 truncate table temp_user_type_session; -- 查询所有用户最新的用户类型数据 SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp WHERE user_type.start_date = temp.latestDate and uid = temp.uid2; -- 获取有差异的数据 select tutl.*,tuts.user_id user_id2, tuts.present_type present_type2, tuts.pay_type pay_type2, tuts.group_type group_type2, tuts.start_date start_date2,tuts.uni_key uni_key2 from temp_user_type_latest tutl left join temp_user_type_session tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type;
基于 Magic-api + Clickhouse 实现业务数据更新的项目记录 背景介绍项目有用到 Clickhouse 作为数仓,存储一些用户日常业务产生的大数据,下面先简单介绍一下我们这个任务的需求背景:我们的每个用户都会归属于某个用户组,并基于用户所在的计费组织实现产品使用过程中的消费等情况。而按照系统的设定用户初始注册时是没有归属用户组的,计费组织的主账号可以在控制台将用户绑定到该计费组下,也可以解绑,解绑后也可以绑定到其他用户组。为了更好的这个变更情况,我们在 Clickhouse 添加了一张名为 user_type 的表,每次该数据变更都会新增一条记录,该表的结构如下:CREATE TABLE user_type ( `user_id` Nullable(String), `present_type` Nullable(String), `pay_type` Nullable(String), `group_type` Nullable(String), `start_date` Nullable(Date), `end_date` Nullable(Date), `uni_key` Nullable(String) ) ENGINE = Log;实现方案本项目初期由使用 dbt + Clickhouse 的方式来实现,但是经实践运行一段时间后发现 dbt 做数据同步很方便,但是要添加一些业务逻辑就显得很棘手。为了解决 dbt 的问题,我们使用已搭建的 magic-api 来实现这个数据的更新,由于相关数据仅需一天一更新即可,所以我们可以直接利用 magic-api 自带的定时任务机制来实现更新。技术细节为便于相关业务逻辑在接口和定时任务中复用,我们将核心代码写在函数模块中:相关步骤核心代码如下步骤:1、从计费系统获取最新的userType信息var statSQL = `select e.*, CONCAT(e.user_id,'-',e.present_type,'-',e.pay_type,'-',e.group_type,'-',date_format(e.start_date,'%Y-%m-%d')) as uni_key FROM( SELECT a.user_id, CASE WHEN EXISTS ( SELECT 1 FROM ( SELECT t1.user_id user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id UNION SELECT u2.user_id user_id from b_user as u1, b_user as u2 where u1.group_id=u2.group_id AND u1.user_id != u2.user_id AND EXISTS( SELECT 1 FROM (SELECT t1.user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id) c WHERE c.user_id = u1.user_id ) ) d WHERE a.user_id = d.user_id ) then 'pay' else 'no pay' END as present_type, CASE WHEN EXISTS( SELECT 1 FROM( SELECT t1.user_id FROM b_user t1 , b_group t2 WHERE t1.user_id=t2.pay_user_id AND t2.pay_user_id IS NOT NULL )b WHERE a.user_id = b.user_id ) THEN 'master' ELSE 'slave' END as pay_type, CASE WHEN EXISTS(SELECT 1 FROM(SELECT t1.user_id FROM b_user t1 WHERE t1.group_id IS NOT NULL)b WHERE a.user_id = b.user_id) THEN 'group' ELSE 'no group' END as group_type, CURRENT_DATE as start_date, DATE(null) as end_date FROM b_user a )e` return db['NB'].select(statSQL)2、将上一步获取到的信息存储到Clickhouse 的一张临时表import log; import cn.hutool.core.date.DateUtil; import '@/statForProduction/userTypeStat/getLatestUserTypeData' as getLatestUserType; // ------------------- 一、创建临时表 ------------------- const TEMP_TABLE_NAME = 'user_type_temp' var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${TEMP_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${TEMP_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${TEMP_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // ------------------- 二、获取最新的用户类型数据 ------------------- log.info(`============ 开始从计费系统获取最新的用户类型数据,该操作耗时较长,请耐心等待 ============`) var timer = DateUtil.timer() const userTypeList = getLatestUserType() log.info(`getLatestUserType cost time: ${timer.intervalPretty()}.`) // ------------------- 三、将数据存入临时表 ------------------- const BATCH_INSERT_COUNT = 1000 // 分批次入临时表,一次插入记录条数 var timer = DateUtil.timer() const allDataCount = userTypeList.size() if (allDataCount > 0) { log.info(`开始导入数据到临时表,待导入的总记录数为:${allDataCount},预计分${Math.ceil(allDataCount/BATCH_INSERT_COUNT)::int}批导入。`) const willInsertArr = [] var insertSQL = `insert into ${TEMP_TABLE_NAME}(user_id,present_type,pay_type,group_type,start_date,end_date,uni_key)` // 分批次插入临时表 for (index,userTypeItem in userTypeList) { willInsertArr.push(`('${userTypeItem.userId}','${userTypeItem.presentType}','${userTypeItem.payType}','${userTypeItem.groupType}','${userTypeItem.startDate}', null,'${userTypeItem.uniKey}')`) if (willInsertArr.size() === BATCH_INSERT_COUNT) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() log.info('Batch insert:' + index) } } // 不满整批次数据单独处理 if (willInsertArr.size() > 0) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() } } log.info(`insert latest user type to Temporary Table cost time: ${timer.intervalPretty()}.`) return true3、将临时表数据跟前一次最新的用户数据对比后,将有变更和新增的数据写入user_type表import log; import cn.hutool.core.date.DateUtil; const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据,已在上一步获取数据完毕 // 一、从user_type表获取所有用户最新的用户类型数据并插入到用于计算的临时表 // 1.1 新建临时表,用于存储每个用户user_type 表中最新的用户类型数据 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // 1.2 将最新数据写入临时表 // 该方式在数据量较大的情况下极有可能导致内存溢出,拟采取其他方案:在user_type 数据初始化的时候,将最新的用户类型数据存储到user_type_latest表,对比更新完成后将临时表的数据更新到user_type_latest便于下次对比 // const insertLatestDataSQL = `insert into ${LATEST_TABLE_NAME} SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key // FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp // WHERE user_type.start_date = temp.latestDate and uid = temp.uid2` // db['CH'].update(insertLatestDataSQL) // 二、两个临时表的数据做对比,并将最新数据更新到 user_type var timer = DateUtil.timer() // 2.1 更新有变更的数据 const changedInsertSQL = `insert into user_type select tuts.* from ${LATEST_TABLE_NAME} tutl left join ${TEMP_TABLE_NAME} tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type` timer.start("insertChangeData") db['CH'].update(changedInsertSQL) // 2.2 新增用户数据直接插入 timer.start("insertNewData") const insertNewUserSQL = `insert into user_type select * from ${TEMP_TABLE_NAME} tuts where tuts.user_id not in (select tutl.user_id from ${LATEST_TABLE_NAME} tutl) ` db['CH'].update(insertNewUserSQL) // 三、如果有数据更新,则将临时表的数据替换latest表 // 3.1 清理已有的数据 const truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) // 3.2 从临时表导入最新的数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) log.info(`insertChangeData cost time: ${timer.intervalPretty('insertChangeData')}`) log.info(`insertNewUser cost time: ${timer.intervalPretty('insertNewData')}`) // 四、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) return true 定义好相关函数后,我们可以直接在接口中用起来了,为此我定义了两个接口,一个接口用于数据初始化,一个接口用于手动更新数据:接口定义01数据初始化import log; import '@/statForProduction/userTypeStat/maintenance/clearUserTypeData' as clearUserTypeData import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据 // 一、清空所有user_type表的数据 clearUserTypeData() // 二、一次性写入所有 saveToTemporaryTable() // 三、将临时表的所有数据一次性写入user_type 表作为初始数据 const initialUserTypeDataSQL = `insert into user_type select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialUserTypeDataSQL) // 四、将数据写入最新用户类型表,便于下一次做数据比对 // 4.1 基于 user_type 表 创建 user_type_latest 表 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张 if (checkExistRes.size() === 0) { var createLatestTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(createLatestTableSQL) } else { // 表存在则先清空表的数据,便于下一步将最新的用户类型数据存入该表 var truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) } // 4.2 插入该表的初始数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) // 五、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) 02手工同步用户类型数据/** * 本接口用于手工临时同步数据用,日常使用定时任务自动同步操作即可 */ import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable import '@/statForProduction/userTypeStat/updateUserTypeData' as updateUserTypeData saveToTemporaryTable() updateUserTypeData()添加定时任务本任务用到的部分 Clickhouse SQL-- 判断数据表是否存在 SELECT 1 FROM system.tables WHERE database = 'dw' AND name = 'temp_user_type_session' -- 根据user_type 表创建一张名为 temp_user_type_session 的临时表 CREATE TABLE temp_user_type_session as user_type; -- 清空某数据表中的所有内容 truncate table temp_user_type_session; -- 查询所有用户最新的用户类型数据 SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp WHERE user_type.start_date = temp.latestDate and uid = temp.uid2; -- 获取有差异的数据 select tutl.*,tuts.user_id user_id2, tuts.present_type present_type2, tuts.pay_type pay_type2, tuts.group_type group_type2, tuts.start_date start_date2,tuts.uni_key uni_key2 from temp_user_type_latest tutl left join temp_user_type_session tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type; -
magic-boot 整合 Clickhouse 及在 magic-api 中的基本使用 项目有用到 Clickhouse 作为数仓, magic-boot 作为万金油般的存在,肯定是需要整合 Clickhouse 获取数据的,下面我们就开始吧。一、整合 clickhouse-jdbc 驱动根据clickhouse 官方文档的指引,在项目的 Maven 依赖管理文件(pom.xml)中的 dependencies 节点添加如下依赖项: <dependency> <groupId>com.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <classifier>all</classifier> <version>0.6.0</version> </dependency>注:dependency 中一定要添加 <classifier>all</classifier>,否则会出现找不到依赖的className的异常二、magic-api 中添加数据源在 magic-api 主界面右侧的 DataSource 面板中,单击「+」按钮,打开「创建数据源」弹出层,如下图所示:相关表单项填写如下:名称:任意,只要自己能区别数据源即可Key:为便于在代码中引用,尽量采用简写URL:jdbc:(ch|clickhouse)[:<protocol>]://endpoint1,endpoint2,...?param1=value1¶m2=value2用户名:用户名密码:密码驱动类:com.clickhouse.jdbc.ClickHouseDriver类型:com.zaxxer.hikari.HikariDataSource。用Hikari 和 Druid 连接池测试都没碰到问题。本次测试填写后的连接池示例如下图所示:在 magic-api 中写测试代码进行功能验证创建数据表db['CH'].update(""" CREATE TABLE test_for_magic_boot ( `id` UUID, `user_name` String, `real_name` String, `birthday` Date, `gender` String ) ENGINE = MergeTree ORDER BY birthday SETTINGS index_granularity = 8192; """);添加测试数据// 添加数据要使用 update方法,使用insert 方法会报错。 // https://gitee.com/ssssssss-team/magic-api/issues/I4SQYW db['CH'].update(`insert into test_for_magic_boot(id,user_name,real_name,birthday,gender) values(#{uuid()},'shiyu', '时羽','1991-12-15', 'F'),(#{uuid()},'lint', '李宁涛','1985-11-19', 'M'),(#{uuid()},'gaowz', '高文中','1968-01-23', 'M')`)修改测试数据db['CH'].update(`update test_no_index set real_name='时大款' where user_name='shiyu'`) Clickhouse 更新操作有一些限制索引列不能进行更新分布式表不能进行更新不适合频繁更新或point更新查询数据return db['CH'].select('select * from test_for_magic_boot')删除数据db['CH'].update(`delete from test_for_magic_boot where user_name='lint'`)删除测试数据表db['CH'].update('drop table test_for_magic_boot');