搜索到
7
篇与
magic-boot
的结果
-
 一个收费图标网站的整站png图标爬取过程记录 近期发现一个还不错的3D图标库(https://www.thiings.co/things)图标偏写实风格,都是png格式,也便于在其他项目中引用,看项目的介绍,有1900个图标,都是偏日常生活物品,可以考虑下载下来,打印给崽做干预训练。官网提供了下载全部的功能,但下载的时候提示需要29美元,且不支持我仅有的国内的银行卡及在线支付方式,又不得不让我望而却步了。所以不得不祭出国内程序员的大杀器:白嫖。以下便是白嫖全过程。页面分析经过对页面源码的分析,发现该网页为使用 Next 开发的单页应用,页面使用 Webpack 打包,滚动页面过程中没有发起异步请求,那相关的文件路径应该是打包在工程里的。经浏览一个图标,发现如下规律:可通过如下URL下载到原始图片:https://lftz25oez4aqbxpq.public.blob.vercel-storage.com/image-UnbACooeDKA5ggSg36Zi8JizoYINpv.png,经过进一步分析,URL 中的 UnbACooeDKA5ggSg36Zi8JizoYINpv 对应的图片的ID。经过进一步分析,我们在源码底部找到了相关资源定义的json数据,经过清洗得到如下精简后的json格式的定义数据:{ "currentPage": "COLLECTION", "shouldShuffle": true, "rootPath": "/things", "canDownload": true, "categories": ["Everyday", "Nature", "Technology", "Sponsors"], "forceLength": 1900, "items": [ { "id": "amphitheater", "name": "Amphitheater", "categories": ["places \u0026 structures", "entertainment", "urban"], "fileId": "oS7mN2q1OPFw7HHZGO30XoFqCjQJba", "shareUrl": "https://www.thiings.co/things/amphitheater" }, { "id": "sofa", "name": "Sofa", "categories": ["everyday life", "furniture", "seating"], "fileId": "cRuokpRSq9ekpqqbJA3w5Tg4DWOyLv", "shareUrl": "https://www.thiings.co/things/sofa" }, { "id": "toaster", "name": "Toaster", "categories": ["everyday life", "appliance", "kitchen"], "fileId": "UnbACooeDKA5ggSg36Zi8JizoYINpv", "shareUrl": "https://www.thiings.co/things/toaster" }, { "id": "bookshelf", "name": "Bookshelf", "categories": ["everyday life", "furniture", "storage"], "fileId": "4r2tNFAParX1lIOupxBEg3fPYP7GuT", "shareUrl": "https://www.thiings.co/things/bookshelf" } ] }由此我们可以遍历json中的items数组获取所有资源,然后拼凑图片URL并逐个下载对应的png原图即可。资源下载这种数据爬取方面的操作,还是采用我最熟练的 magic-api 来实现,主要分两个步骤:1、解析json文件并将文件入库为了便于后续资源利用,我们将上面的json数据保存到MySQL中,建表语句如下:-- zzl_resources.things_icons definition CREATE TABLE `things_icons` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', `oid` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '原始id', `name` varchar(200) COLLATE utf8mb4_general_ci NOT NULL COMMENT '名称', `categories` varchar(500) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'json数组', `categories_str` varchar(500) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '便于按类别搜索的字符串', `file_id` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '文件Id', `share_url` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '详情URL', `note` varchar(2000) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '详情页的描述信息', `add_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='https://www.thiings.co/things 网站的图标爬取专用';由于json数据较大,我们将数据保存在磁盘文件中(things_resources.json),然后读取解析保存入库,代码如下:import cn.hutool.core.io.FileUtil import cn.hutool.core.date.DateTime import cn.hutool.core.date.DateUtil import org.jsoup.helper.DataUtil import cn.hutool.json.JSONUtil import cn.hutool.core.util.ObjectUtil import cn.hutool.core.util.StrUtil import log var timer = DateUtil.timer(); var jsonStr = FileUtil.readString("/cosmos/apps/uploads/things_resources.json","UTF-8"); var things = JSONUtil.parseArray(jsonStr) // log.info('jsonStr:' + jsonStr) for (thingItem in things) { var categoriesStr = '' if (thingItem.categories && thingItem.categories.length > 0) { categoriesStr = "," + thingItem.categories.join(',') + "," } if (!thingItem.shareUrl) { log.info('跳过入库:' + thingItem.fileId) continue } var data = { oid: thingItem.id, name: thingItem.name, categories: JSONUtil.toJsonStr(thingItem.categories), categoriesStr: categoriesStr, fileId: thingItem.fileId, shareUrl: thingItem.shareUrl } log.info(JSONUtil.toJsonStr(data)) db['ZR'].table('things_icons').insert(data) } log.info(`Cost Time: ${timer.intervalPretty()}.`); return '操作成功'2、下载相关的原图数据保存入库后,我们可以遍历记录,然后下载到指定目录,一下是下载代码:import cn.hutool.http.HttpUtil import cn.hutool.core.io.FileUtil import cn.hutool.core.date.DateTime import cn.hutool.core.date.DateUtil import org.jsoup.helper.DataUtil import cn.hutool.json.JSONUtil import log import http var list = db['ZR'].table('things_icons').select() var index = 0 var size = list.size() var timer = DateUtil.timer(); for ( item in list) { var fileId = item.fileId var url = `https://lftz25oez4aqbxpq.public.blob.vercel-storage.com/image-${fileId}.png` try { HttpUtil.downloadFileFromUrl(url, `/cosmos/apps/uploads/things-icons/${item.name}__${fileId}.png`) } catch(e) { log.info(`something error:${item.fileId}`) } index++ log.info(`index/size:${index}/${size}`) } log.info(`Cost Time: ${timer.intervalPretty()}.`); return 'success'执行该方法后,耗时 1小时46分。下载了 1908 张图片,共计 2.78G通过对下载的图片进行统计,发现所有png图片均为1024*1024的分辨率,每张图片基本上都在1M以上,只要不涉及商用版权纠纷的场景,这样规范的图片可以直接用在很多地方。
一个收费图标网站的整站png图标爬取过程记录 近期发现一个还不错的3D图标库(https://www.thiings.co/things)图标偏写实风格,都是png格式,也便于在其他项目中引用,看项目的介绍,有1900个图标,都是偏日常生活物品,可以考虑下载下来,打印给崽做干预训练。官网提供了下载全部的功能,但下载的时候提示需要29美元,且不支持我仅有的国内的银行卡及在线支付方式,又不得不让我望而却步了。所以不得不祭出国内程序员的大杀器:白嫖。以下便是白嫖全过程。页面分析经过对页面源码的分析,发现该网页为使用 Next 开发的单页应用,页面使用 Webpack 打包,滚动页面过程中没有发起异步请求,那相关的文件路径应该是打包在工程里的。经浏览一个图标,发现如下规律:可通过如下URL下载到原始图片:https://lftz25oez4aqbxpq.public.blob.vercel-storage.com/image-UnbACooeDKA5ggSg36Zi8JizoYINpv.png,经过进一步分析,URL 中的 UnbACooeDKA5ggSg36Zi8JizoYINpv 对应的图片的ID。经过进一步分析,我们在源码底部找到了相关资源定义的json数据,经过清洗得到如下精简后的json格式的定义数据:{ "currentPage": "COLLECTION", "shouldShuffle": true, "rootPath": "/things", "canDownload": true, "categories": ["Everyday", "Nature", "Technology", "Sponsors"], "forceLength": 1900, "items": [ { "id": "amphitheater", "name": "Amphitheater", "categories": ["places \u0026 structures", "entertainment", "urban"], "fileId": "oS7mN2q1OPFw7HHZGO30XoFqCjQJba", "shareUrl": "https://www.thiings.co/things/amphitheater" }, { "id": "sofa", "name": "Sofa", "categories": ["everyday life", "furniture", "seating"], "fileId": "cRuokpRSq9ekpqqbJA3w5Tg4DWOyLv", "shareUrl": "https://www.thiings.co/things/sofa" }, { "id": "toaster", "name": "Toaster", "categories": ["everyday life", "appliance", "kitchen"], "fileId": "UnbACooeDKA5ggSg36Zi8JizoYINpv", "shareUrl": "https://www.thiings.co/things/toaster" }, { "id": "bookshelf", "name": "Bookshelf", "categories": ["everyday life", "furniture", "storage"], "fileId": "4r2tNFAParX1lIOupxBEg3fPYP7GuT", "shareUrl": "https://www.thiings.co/things/bookshelf" } ] }由此我们可以遍历json中的items数组获取所有资源,然后拼凑图片URL并逐个下载对应的png原图即可。资源下载这种数据爬取方面的操作,还是采用我最熟练的 magic-api 来实现,主要分两个步骤:1、解析json文件并将文件入库为了便于后续资源利用,我们将上面的json数据保存到MySQL中,建表语句如下:-- zzl_resources.things_icons definition CREATE TABLE `things_icons` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', `oid` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '原始id', `name` varchar(200) COLLATE utf8mb4_general_ci NOT NULL COMMENT '名称', `categories` varchar(500) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'json数组', `categories_str` varchar(500) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '便于按类别搜索的字符串', `file_id` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '文件Id', `share_url` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '详情URL', `note` varchar(2000) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '详情页的描述信息', `add_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='https://www.thiings.co/things 网站的图标爬取专用';由于json数据较大,我们将数据保存在磁盘文件中(things_resources.json),然后读取解析保存入库,代码如下:import cn.hutool.core.io.FileUtil import cn.hutool.core.date.DateTime import cn.hutool.core.date.DateUtil import org.jsoup.helper.DataUtil import cn.hutool.json.JSONUtil import cn.hutool.core.util.ObjectUtil import cn.hutool.core.util.StrUtil import log var timer = DateUtil.timer(); var jsonStr = FileUtil.readString("/cosmos/apps/uploads/things_resources.json","UTF-8"); var things = JSONUtil.parseArray(jsonStr) // log.info('jsonStr:' + jsonStr) for (thingItem in things) { var categoriesStr = '' if (thingItem.categories && thingItem.categories.length > 0) { categoriesStr = "," + thingItem.categories.join(',') + "," } if (!thingItem.shareUrl) { log.info('跳过入库:' + thingItem.fileId) continue } var data = { oid: thingItem.id, name: thingItem.name, categories: JSONUtil.toJsonStr(thingItem.categories), categoriesStr: categoriesStr, fileId: thingItem.fileId, shareUrl: thingItem.shareUrl } log.info(JSONUtil.toJsonStr(data)) db['ZR'].table('things_icons').insert(data) } log.info(`Cost Time: ${timer.intervalPretty()}.`); return '操作成功'2、下载相关的原图数据保存入库后,我们可以遍历记录,然后下载到指定目录,一下是下载代码:import cn.hutool.http.HttpUtil import cn.hutool.core.io.FileUtil import cn.hutool.core.date.DateTime import cn.hutool.core.date.DateUtil import org.jsoup.helper.DataUtil import cn.hutool.json.JSONUtil import log import http var list = db['ZR'].table('things_icons').select() var index = 0 var size = list.size() var timer = DateUtil.timer(); for ( item in list) { var fileId = item.fileId var url = `https://lftz25oez4aqbxpq.public.blob.vercel-storage.com/image-${fileId}.png` try { HttpUtil.downloadFileFromUrl(url, `/cosmos/apps/uploads/things-icons/${item.name}__${fileId}.png`) } catch(e) { log.info(`something error:${item.fileId}`) } index++ log.info(`index/size:${index}/${size}`) } log.info(`Cost Time: ${timer.intervalPretty()}.`); return 'success'执行该方法后,耗时 1小时46分。下载了 1908 张图片,共计 2.78G通过对下载的图片进行统计,发现所有png图片均为1024*1024的分辨率,每张图片基本上都在1M以上,只要不涉及商用版权纠纷的场景,这样规范的图片可以直接用在很多地方。 -
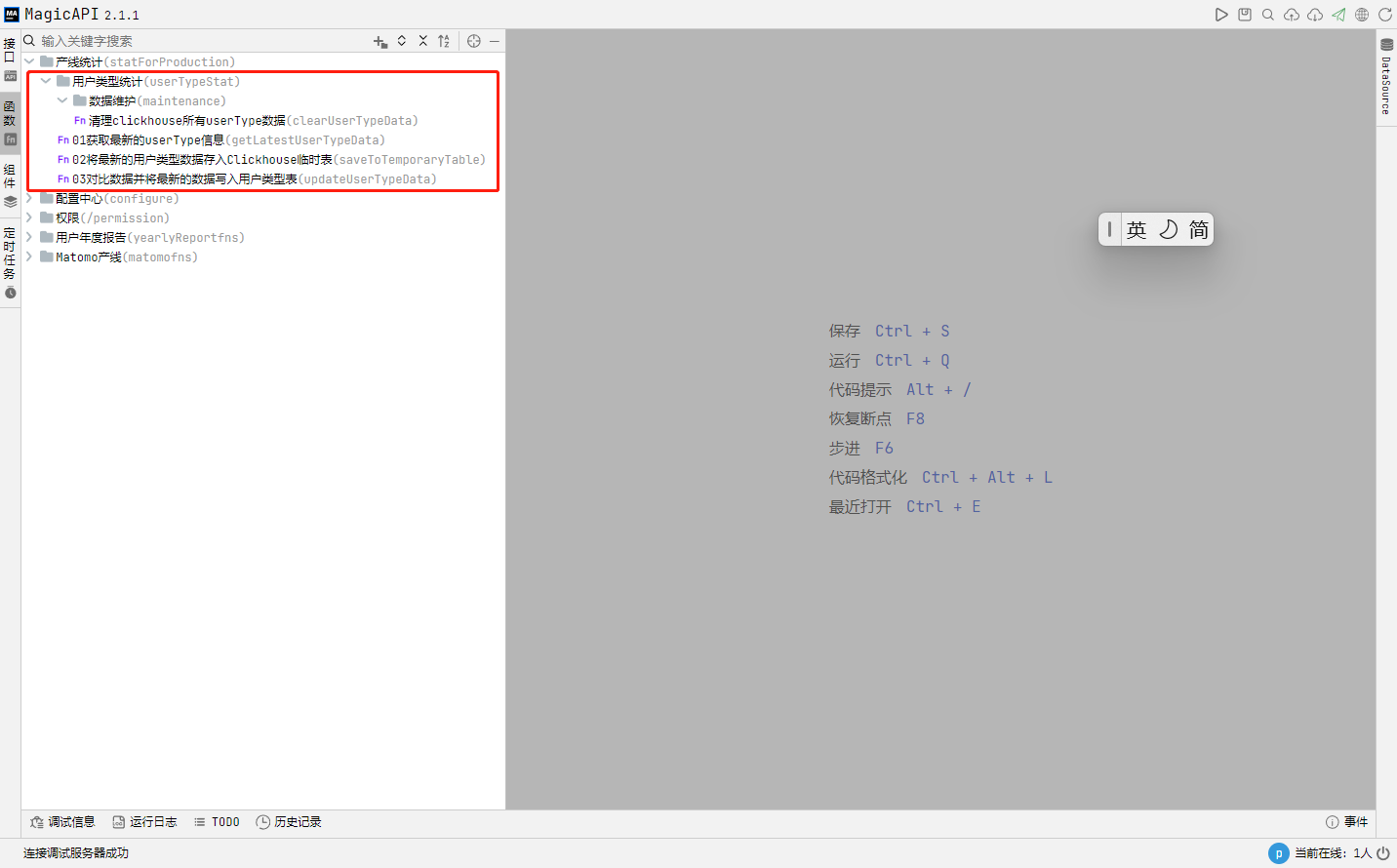
基于 Magic-api + Clickhouse 实现业务数据更新的项目记录 背景介绍项目有用到 Clickhouse 作为数仓,存储一些用户日常业务产生的大数据,下面先简单介绍一下我们这个任务的需求背景:我们的每个用户都会归属于某个用户组,并基于用户所在的计费组织实现产品使用过程中的消费等情况。而按照系统的设定用户初始注册时是没有归属用户组的,计费组织的主账号可以在控制台将用户绑定到该计费组下,也可以解绑,解绑后也可以绑定到其他用户组。为了更好的这个变更情况,我们在 Clickhouse 添加了一张名为 user_type 的表,每次该数据变更都会新增一条记录,该表的结构如下:CREATE TABLE user_type ( `user_id` Nullable(String), `present_type` Nullable(String), `pay_type` Nullable(String), `group_type` Nullable(String), `start_date` Nullable(Date), `end_date` Nullable(Date), `uni_key` Nullable(String) ) ENGINE = Log;实现方案本项目初期由使用 dbt + Clickhouse 的方式来实现,但是经实践运行一段时间后发现 dbt 做数据同步很方便,但是要添加一些业务逻辑就显得很棘手。为了解决 dbt 的问题,我们使用已搭建的 magic-api 来实现这个数据的更新,由于相关数据仅需一天一更新即可,所以我们可以直接利用 magic-api 自带的定时任务机制来实现更新。技术细节为便于相关业务逻辑在接口和定时任务中复用,我们将核心代码写在函数模块中:相关步骤核心代码如下步骤:1、从计费系统获取最新的userType信息var statSQL = `select e.*, CONCAT(e.user_id,'-',e.present_type,'-',e.pay_type,'-',e.group_type,'-',date_format(e.start_date,'%Y-%m-%d')) as uni_key FROM( SELECT a.user_id, CASE WHEN EXISTS ( SELECT 1 FROM ( SELECT t1.user_id user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id UNION SELECT u2.user_id user_id from b_user as u1, b_user as u2 where u1.group_id=u2.group_id AND u1.user_id != u2.user_id AND EXISTS( SELECT 1 FROM (SELECT t1.user_id from b_contract t1 LEFT JOIN b_contract_item t2 ON t1.id = t2.contract_id WHERE t2.is_present = 0 and t2.received_payments > 0 GROUP BY t1.user_id) c WHERE c.user_id = u1.user_id ) ) d WHERE a.user_id = d.user_id ) then 'pay' else 'no pay' END as present_type, CASE WHEN EXISTS( SELECT 1 FROM( SELECT t1.user_id FROM b_user t1 , b_group t2 WHERE t1.user_id=t2.pay_user_id AND t2.pay_user_id IS NOT NULL )b WHERE a.user_id = b.user_id ) THEN 'master' ELSE 'slave' END as pay_type, CASE WHEN EXISTS(SELECT 1 FROM(SELECT t1.user_id FROM b_user t1 WHERE t1.group_id IS NOT NULL)b WHERE a.user_id = b.user_id) THEN 'group' ELSE 'no group' END as group_type, CURRENT_DATE as start_date, DATE(null) as end_date FROM b_user a )e` return db['NB'].select(statSQL)2、将上一步获取到的信息存储到Clickhouse 的一张临时表import log; import cn.hutool.core.date.DateUtil; import '@/statForProduction/userTypeStat/getLatestUserTypeData' as getLatestUserType; // ------------------- 一、创建临时表 ------------------- const TEMP_TABLE_NAME = 'user_type_temp' var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${TEMP_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${TEMP_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${TEMP_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // ------------------- 二、获取最新的用户类型数据 ------------------- log.info(`============ 开始从计费系统获取最新的用户类型数据,该操作耗时较长,请耐心等待 ============`) var timer = DateUtil.timer() const userTypeList = getLatestUserType() log.info(`getLatestUserType cost time: ${timer.intervalPretty()}.`) // ------------------- 三、将数据存入临时表 ------------------- const BATCH_INSERT_COUNT = 1000 // 分批次入临时表,一次插入记录条数 var timer = DateUtil.timer() const allDataCount = userTypeList.size() if (allDataCount > 0) { log.info(`开始导入数据到临时表,待导入的总记录数为:${allDataCount},预计分${Math.ceil(allDataCount/BATCH_INSERT_COUNT)::int}批导入。`) const willInsertArr = [] var insertSQL = `insert into ${TEMP_TABLE_NAME}(user_id,present_type,pay_type,group_type,start_date,end_date,uni_key)` // 分批次插入临时表 for (index,userTypeItem in userTypeList) { willInsertArr.push(`('${userTypeItem.userId}','${userTypeItem.presentType}','${userTypeItem.payType}','${userTypeItem.groupType}','${userTypeItem.startDate}', null,'${userTypeItem.uniKey}')`) if (willInsertArr.size() === BATCH_INSERT_COUNT) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() log.info('Batch insert:' + index) } } // 不满整批次数据单独处理 if (willInsertArr.size() > 0) { db['CH'].update(`${insertSQL} values${willInsertArr.join(',')}`) // 清空数据 willInsertArr.clear() } } log.info(`insert latest user type to Temporary Table cost time: ${timer.intervalPretty()}.`) return true3、将临时表数据跟前一次最新的用户数据对比后,将有变更和新增的数据写入user_type表import log; import cn.hutool.core.date.DateUtil; const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据,已在上一步获取数据完毕 // 一、从user_type表获取所有用户最新的用户类型数据并插入到用于计算的临时表 // 1.1 新建临时表,用于存储每个用户user_type 表中最新的用户类型数据 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张临时表 if (checkExistRes.size() === 0) { var initTemporaryTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(initTemporaryTableSQL) } else { // 临时表存在则先清空临时表的数据,便于下一步将输入存入临时表 var truncateTemporaryTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateTemporaryTableSQL) } // 1.2 将最新数据写入临时表 // 该方式在数据量较大的情况下极有可能导致内存溢出,拟采取其他方案:在user_type 数据初始化的时候,将最新的用户类型数据存储到user_type_latest表,对比更新完成后将临时表的数据更新到user_type_latest便于下次对比 // const insertLatestDataSQL = `insert into ${LATEST_TABLE_NAME} SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key // FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp // WHERE user_type.start_date = temp.latestDate and uid = temp.uid2` // db['CH'].update(insertLatestDataSQL) // 二、两个临时表的数据做对比,并将最新数据更新到 user_type var timer = DateUtil.timer() // 2.1 更新有变更的数据 const changedInsertSQL = `insert into user_type select tuts.* from ${LATEST_TABLE_NAME} tutl left join ${TEMP_TABLE_NAME} tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type` timer.start("insertChangeData") db['CH'].update(changedInsertSQL) // 2.2 新增用户数据直接插入 timer.start("insertNewData") const insertNewUserSQL = `insert into user_type select * from ${TEMP_TABLE_NAME} tuts where tuts.user_id not in (select tutl.user_id from ${LATEST_TABLE_NAME} tutl) ` db['CH'].update(insertNewUserSQL) // 三、如果有数据更新,则将临时表的数据替换latest表 // 3.1 清理已有的数据 const truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) // 3.2 从临时表导入最新的数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) log.info(`insertChangeData cost time: ${timer.intervalPretty('insertChangeData')}`) log.info(`insertNewUser cost time: ${timer.intervalPretty('insertNewData')}`) // 四、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) return true 定义好相关函数后,我们可以直接在接口中用起来了,为此我定义了两个接口,一个接口用于数据初始化,一个接口用于手动更新数据:接口定义01数据初始化import log; import '@/statForProduction/userTypeStat/maintenance/clearUserTypeData' as clearUserTypeData import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable const LATEST_TABLE_NAME = 'user_type_latest' // 用户最新类型数据表 const TEMP_TABLE_NAME = 'user_type_temp' // 该表存储从计费表获取到用户当前的用户类型数据 // 一、清空所有user_type表的数据 clearUserTypeData() // 二、一次性写入所有 saveToTemporaryTable() // 三、将临时表的所有数据一次性写入user_type 表作为初始数据 const initialUserTypeDataSQL = `insert into user_type select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialUserTypeDataSQL) // 四、将数据写入最新用户类型表,便于下一次做数据比对 // 4.1 基于 user_type 表 创建 user_type_latest 表 var checkExistRes = db['CH'].select(`SELECT 1 FROM system.tables WHERE database = 'dw' AND name = '${LATEST_TABLE_NAME}'`) log.info(checkExistRes.size() + '') // 不存在表的话就基于 user_type 表创建一张 if (checkExistRes.size() === 0) { var createLatestTableSQL = `CREATE TABLE ${LATEST_TABLE_NAME} as user_type` db['CH'].update(createLatestTableSQL) } else { // 表存在则先清空表的数据,便于下一步将最新的用户类型数据存入该表 var truncateLatestTableSQL = `truncate table ${LATEST_TABLE_NAME}` db['CH'].update(truncateLatestTableSQL) } // 4.2 插入该表的初始数据 const initialLatestTableDataSQL = `insert into ${LATEST_TABLE_NAME} select * from ${TEMP_TABLE_NAME}` db['CH'].update(initialLatestTableDataSQL) // 五、清理临时表 const dropTempTableSQL = `drop table ${TEMP_TABLE_NAME}` db['CH'].update(dropTempTableSQL) 02手工同步用户类型数据/** * 本接口用于手工临时同步数据用,日常使用定时任务自动同步操作即可 */ import '@/statForProduction/userTypeStat/saveToTemporaryTable' as saveToTemporaryTable import '@/statForProduction/userTypeStat/updateUserTypeData' as updateUserTypeData saveToTemporaryTable() updateUserTypeData()添加定时任务本任务用到的部分 Clickhouse SQL-- 判断数据表是否存在 SELECT 1 FROM system.tables WHERE database = 'dw' AND name = 'temp_user_type_session' -- 根据user_type 表创建一张名为 temp_user_type_session 的临时表 CREATE TABLE temp_user_type_session as user_type; -- 清空某数据表中的所有内容 truncate table temp_user_type_session; -- 查询所有用户最新的用户类型数据 SELECT user_type.user_id uid,user_type.present_type ,user_type.pay_type ,user_type.group_type,user_type.start_date,user_type.end_date,user_type.uni_key FROM user_type, (SELECT user_type.user_id uid2,max(user_type.start_date) AS latestDate FROM user_type GROUP BY user_type.user_id) AS temp WHERE user_type.start_date = temp.latestDate and uid = temp.uid2; -- 获取有差异的数据 select tutl.*,tuts.user_id user_id2, tuts.present_type present_type2, tuts.pay_type pay_type2, tuts.group_type group_type2, tuts.start_date start_date2,tuts.uni_key uni_key2 from temp_user_type_latest tutl left join temp_user_type_session tuts on tutl.user_id =tuts.user_id where tutl.present_type != tuts.present_type or tutl.pay_type != tuts.pay_type or tutl.group_type != tuts.group_type;
-
-
-
-
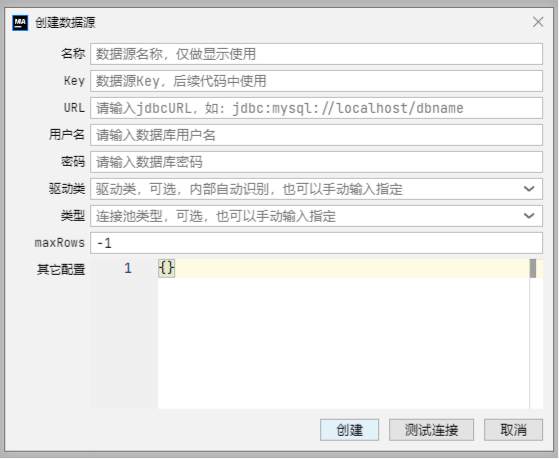
magic-boot 整合 Clickhouse 及在 magic-api 中的基本使用 项目有用到 Clickhouse 作为数仓, magic-boot 作为万金油般的存在,肯定是需要整合 Clickhouse 获取数据的,下面我们就开始吧。一、整合 clickhouse-jdbc 驱动根据clickhouse 官方文档的指引,在项目的 Maven 依赖管理文件(pom.xml)中的 dependencies 节点添加如下依赖项: <dependency> <groupId>com.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <classifier>all</classifier> <version>0.6.0</version> </dependency>注:dependency 中一定要添加 <classifier>all</classifier>,否则会出现找不到依赖的className的异常二、magic-api 中添加数据源在 magic-api 主界面右侧的 DataSource 面板中,单击「+」按钮,打开「创建数据源」弹出层,如下图所示:相关表单项填写如下:名称:任意,只要自己能区别数据源即可Key:为便于在代码中引用,尽量采用简写URL:jdbc:(ch|clickhouse)[:<protocol>]://endpoint1,endpoint2,...?param1=value1¶m2=value2用户名:用户名密码:密码驱动类:com.clickhouse.jdbc.ClickHouseDriver类型:com.zaxxer.hikari.HikariDataSource。用Hikari 和 Druid 连接池测试都没碰到问题。本次测试填写后的连接池示例如下图所示:在 magic-api 中写测试代码进行功能验证创建数据表db['CH'].update(""" CREATE TABLE test_for_magic_boot ( `id` UUID, `user_name` String, `real_name` String, `birthday` Date, `gender` String ) ENGINE = MergeTree ORDER BY birthday SETTINGS index_granularity = 8192; """);添加测试数据// 添加数据要使用 update方法,使用insert 方法会报错。 // https://gitee.com/ssssssss-team/magic-api/issues/I4SQYW db['CH'].update(`insert into test_for_magic_boot(id,user_name,real_name,birthday,gender) values(#{uuid()},'shiyu', '时羽','1991-12-15', 'F'),(#{uuid()},'lint', '李宁涛','1985-11-19', 'M'),(#{uuid()},'gaowz', '高文中','1968-01-23', 'M')`)修改测试数据db['CH'].update(`update test_no_index set real_name='时大款' where user_name='shiyu'`) Clickhouse 更新操作有一些限制索引列不能进行更新分布式表不能进行更新不适合频繁更新或point更新查询数据return db['CH'].select('select * from test_for_magic_boot')删除数据db['CH'].update(`delete from test_for_magic_boot where user_name='lint'`)删除测试数据表db['CH'].update('drop table test_for_magic_boot');
-
magic-boot/magic-api 使用随记 magic-api 是一款非常优秀的快速开发框架,在做大屏的过程中找到的宝贝应用,可以用类JS 语法快速开发接口,能非常方便的操作数据库及处理一些复杂的业务逻辑,而 magic-boot 是基于 magic-api 开发的一款快速开发平台,提供了基本的用户鉴权、后台管理等功能。在实际项目过程中我基于 magic-boot 做了如下事项:1、通过Matomo的API定时同步数据至数仓做大数据分析2、采集coolshell.cn整站数据3、每周五定时推送企业微信消息,提醒同事写周报更多功能待进一步挖掘……下面是我在项目中有用到的技术点的一个记录,会在项目过程中不断更新,便于后续有其他项目用到的话,能快速查找运用。获取 系统设置/配置中心 模块设置的配置项import '@/configure/getBykey' as configure; var baseURL = configure('matomo.base-url'); var authToken = configure('matomo.auth-token');http请求数据示例import cn.hutool.json.JSONUtil import org.springframework.util.StringUtils import http; import log; import '@/configure/getBykey' as configure; // 从配置中心获取接口所需数据 var baseURL = configure('matomo.base-url'); var authToken = configure('matomo.auth-token'); // 组转请求URL var reqURL = `${baseURL}?module=API&method=${method}&format=JSON&token_auth=${authToken}`; if (!StringUtils.isEmpty(params)) { reqURL += `&${params}`; } log.info(`reqURL:${reqURL}`); // 请求数据 var resData = http.connect(reqURL).contentType('application/json').get().getBody(); return resData;在原基础上增加http请求出错重试机制import cn.hutool.json.JSONUtil import org.springframework.util.StringUtils import cn.hutool.core.date.DateUtil import cn.hutool.core.thread.ThreadUtil import http import log import '@/configure/getBykey' as configure; // 从配置中心获取接口所需数据 var baseURL = configure('matomo.base-url'); var authToken = configure('matomo.auth-token'); // 组转请求URL var reqURL = `${baseURL}?module=API&method=${method}&format=JSON&token_auth=${authToken}`; if (!StringUtils.isEmpty(params)) { reqURL += `&${params}`; } // log.info(`reqURL:${reqURL}`); var requestStartTime = DateUtil.now(); var successFlag = '' var exceptionContent = '' // 请求数据 var resData = '' // 最大重试次数 var MAX_RETRY_COUNT = 5 // 当前重试次数 var retryCount = 0; while(retryCount < MAX_RETRY_COUNT && successFlag !== 'Y') { try { resData = http.connect(reqURL).contentType('application/json').get().getBody(); successFlag = 'Y' } catch(e) { successFlag = 'N' ThreadUtil.sleep(1000); retryCount++ exceptionContent = e.getMessage(); } } var requestEndTime = DateUtil.now(); db.table('matomo_sync_log').insert({ 'apiMethod' : method, 'requestParams' : params, 'responseContent': resData.asString(), 'exceptionContent': exceptionContent, 'requestTime':requestStartTime, 'responseTime': requestEndTime, 'retryCount':retryCount, 'successFlag': successFlag}); return resData;分页获取数据在获取一些详情数据的时候,存在数据量超大的情况,一次性获取所有数据极有可能会导致数据库及应用挂掉,即便不挂掉的情况下,也会超长事件才会响应结果,所以采用分页获取还是很有必要的。下面的代码是在实际项目中分页调用Matomo的接口获取输入然后将接口返回的数据,结构化处理后,保存到本地数据库。 import cn.hutool.json.JSONUtil import log; import '@/dmcfns/sendMatomoRequest' as getMatomoData; var PAGE_SIZE=10 // 每页获取记录数,获取后批量入库 var currentPage = 0// 当前页 var needLoad = true // 继续加载数据标识,当当前页加载的内容小于PAGE_SIZE时则不再加载 while(needLoad) { var resData = getMatomoData('Live.getLastVisitsDetails', `period=day&date=${date}&idSite=${siteId}&doNotFetchActions=1&filter_offset=${PAGE_SIZE * currentPage}&filter_limit=${PAGE_SIZE}`) if (resData.asString().startsWith("[")) { var siteDatas = JSONUtil.parseArray(resData); var siteData = []; for (index, site in siteDatas) { var siteObj = siteDatas.getJSONObject(index); var visitId = siteObj.getStr("idVisit"); var visitorId = siteObj.getStr("visitorId"); var visitIp = siteObj.getStr("visitIp"); var longitude = siteObj.getStr("longitude"); var latitude = siteObj.getStr("latitude"); var userId = siteObj.getStr("userId"); var country = siteObj.getStr("country"); var referrerName = siteObj.getStr("referrerName"); var visitProps = JSONUtil.toJsonStr(siteObj); db.table('matomo_daily_visit').insert({ date, siteId, visitId, visitorId, visitIp, longitude, latitude, userId, country, referrerName, visitProps }) } if (siteDatas.size() === PAGE_SIZE) { currentPage++ } else { needLoad = false } } }使用多数据源操作数据库db['ZR'].table('crawler_list').insert({ pageURL: linkURL, articleTitle:linkTitle })根据主键更新部分字段内容var updateMap = { id: visitItem.id, ipCountry: country, ipProvince: province, ipCity: city } db.table('matomo_daily_visit').primary('id').update(updateMap)修改某个字段的值db.table("sys_user").column("isLogin", isLogin).where().eq("id",id).update()推送消息至企业微信机器人import http import log // 测试机器人 // var ROBOT_URL = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx' // 超算云研发部2023 微信群的eHour 机器人 var ROBOT_URL = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxx' var msg = { "msgtype": "text", "text": { "content": """为便于公司开展项目成本核算相关工作,请各位同事及时登录eHour系统录入本周工作工时,如有系统使用相关问题可联系 XXX,感谢配合[抱拳][抱拳]\neHour系统链接如下:http://172.18.3.xxx/""", "mentioned_list":["@all"] } } http.connect(ROBOT_URL).body(msg).post(); log.info('eHour消息推送成功') // 以下cron表达式为每周五16:30分执行 00 30 16 * * 05读取Excel文件并转换为jsonimport cn.hutool.poi.excel.ExcelUtil import request import log var datas = ExcelUtil.getReader(new ByteArrayInputStream(request.getFile('file').getBytes())).readAll() var sourceDatas = datas::stringify::json导出Excelimport cn.hutool.poi.excel.ExcelWriter; import cn.hutool.poi.excel.ExcelUtil; import cn.hutool.json.JSONUtil; import log; import response import java.io.*; var list = db['MDC'].select("select * from crawler_resource limit 10") //通过hutool工具创建的excel的writer,默认为xls格式 ExcelWriter writer= ExcelUtil.getWriter(); var bos = new ByteArrayOutputStream(); log.info("List:\n" + JSONUtil.toJsonPrettyStr(list)) try { //一次性写出内容,使用默认样式,强制输出标题 writer.write(list,true); writer.flush(bos,true); } finally { bos.flush(); writer.close(); } return response.download(bos.toByteArray(), "crawler_resource_list.xlsx");导出Excel时自定义头部import cn.hutool.poi.excel.ExcelWriter; import cn.hutool.poi.excel.ExcelUtil; import cn.hutool.json.JSONUtil; import cn.hutool.core.date.DateUtil import log; import response import java.io.*; var currentDb = db['MS'] var taskObj = currentDb.table('ai_resource_task').where().eq("id",taskId).selectOne() if (taskObj == null) { return "分析任务Id不存在,请修改请求接口后重试" } var pageList = currentDb.select('select * from ai_resource_cost where task_id = #{taskId}') const res = [] pageList.forEach(item => { var userObj = { "用户ID": item.userId, "集群ID":item.clusterId, "资源ID": item.resourceUuid, "资源状态": item.recordType, "开始时间": DateUtil.formatDateTime(DateUtil.date(item.startTime)), "结束时间": DateUtil.formatDateTime(DateUtil.date(item.endTime)), "耗时(单位:秒)": item.costSeconds, "耗时": item.costTimeShow, "计费类型": item.billingType, "资源规格": item.resourceScale, } res.push(userObj) }) ExcelWriter writer= ExcelUtil.getWriter(); writer.setColumnWidth(-1, 18); var bos = new ByteArrayOutputStream(); try { //一次性写出内容,使用默认样式,强制输出标题 writer.write(res,true); writer.flush(bos,true); } finally { bos.flush(); writer.close(); } return response.download(bos.toByteArray(), taskObj.taskName + "_分析结果.xlsx");数据库事务处理db.transaction(() => { if (archived_at == null) { //项目取消归档 //推送取消归档的通知 db.table("project_tasks").primary("project_id").primary("archived_follow").update({ project_id: project_id, archived_follow: 1, archived_at: null, archived_follow: 0, }) } else { //项目归档 db.table("project_tasks").primary("project_id").primary("archived_at").update({ project_id: project_id, archived_at: null, archived_at: archived_at, archived_follow: 1, }) } db.table("projects").primary("id").update({ id: project_id, archived_at: archived_at, archived_userid: userid }) })